English
English
# Basic Concept
uniCloud provides a document database in JSON format. As the name suggests, each record in the database is a JSON-formatted document.
It is a nosql non-relational database. If you are familiar with sql relational database before, the corresponding relationship between the two concepts is as follows:
| Relational | JSON Document |
|---|---|
| database database | database database |
| table table | collection collection. But it is also often referred to as a "table" in the industry. No need to distinguish |
| row row | record record / doc |
| Field column / field | Field field |
| Use sql syntax | Use MongoDB syntax or jql syntax |
- an
uniCloudservice space with one and only one database; - A database can have multiple tables;
- A table can have multiple records;
- A record can have multiple fields.
For example, there is a table in the database, named user, which stores user information. The data content of table user is as follows:
{"name":"张三","tel":"13900000000"}
{"name":"李四","tel":"13911111111"}
In the above data, each row of data represents information of one user, which is called "record/doc". name and tel are called "fields". And "13900000000" is the value of the field tel of the first record.
Each row of records is a complete json document. After getting the records, you can use the normal json method to operate. However, a table is not a json document. A table is a summary of multiple json documents. To obtain a table, a dedicated API is required.
Different from the two-dimensional table format of the relational database, the json document database supports different records with different fields and supports multiple layers of nested data.
Still taking the user table as an example, to store each login time and login ip of each person in the database, it becomes as follows:
{
"name":"张三","tel":"13900000000",
"login_log":[
{"login_date":1604186605445,"login_ip":"192.168.1.1"},
{"login_date":1604186694137,"login_ip":"192.168.1.2"}
]
}
{"name":"李四","tel":"13911111111"}
The above data indicates that Zhang San has logged in twice, the value in login_date is in timestamp format, and timestamp is a numeric data in the database. And Li Si has never logged in.
It can be seen that the json document database is more flexible than the relational database. Li Si may not have the login_log field, or it may have this field, but the number of login records is different from that of Zhang San.
This is just an example. In actual business, it is more appropriate to store the login log in another table separately
For beginners, if you do not understand database design, you can refer to opendb, which has preset a large number of common database designs.
For js engineers who are not familiar with traditional databases but master json, the cloud database of uniCloud is more friendly and does not have the high learning cost of traditional databases.
When creating a new table in the uniCloud web console, you can also select various opendb table templates from the templates below and create them directly.
uniCloud supports both Alibaba Cloud and Tencent Cloud, and their databases are roughly the same, with minor differences. Alibaba Cloud's database is mongoDB4.0, while Tencent Cloud uses a self-developed document database (compatible with mongoDB 4.0 version). uniCloud basically smoothes out the differences between different cloud vendors, and the differences will be marked separately in the document.
# Create the first table
Open the uniCloud web console https://unicloud.dcloud.net.cn/
Create or enter an existing service space, select Cloud Database -> Cloud Database, and create a new table
For example, let's create a resume table called resume. Click the Create button on the right above.
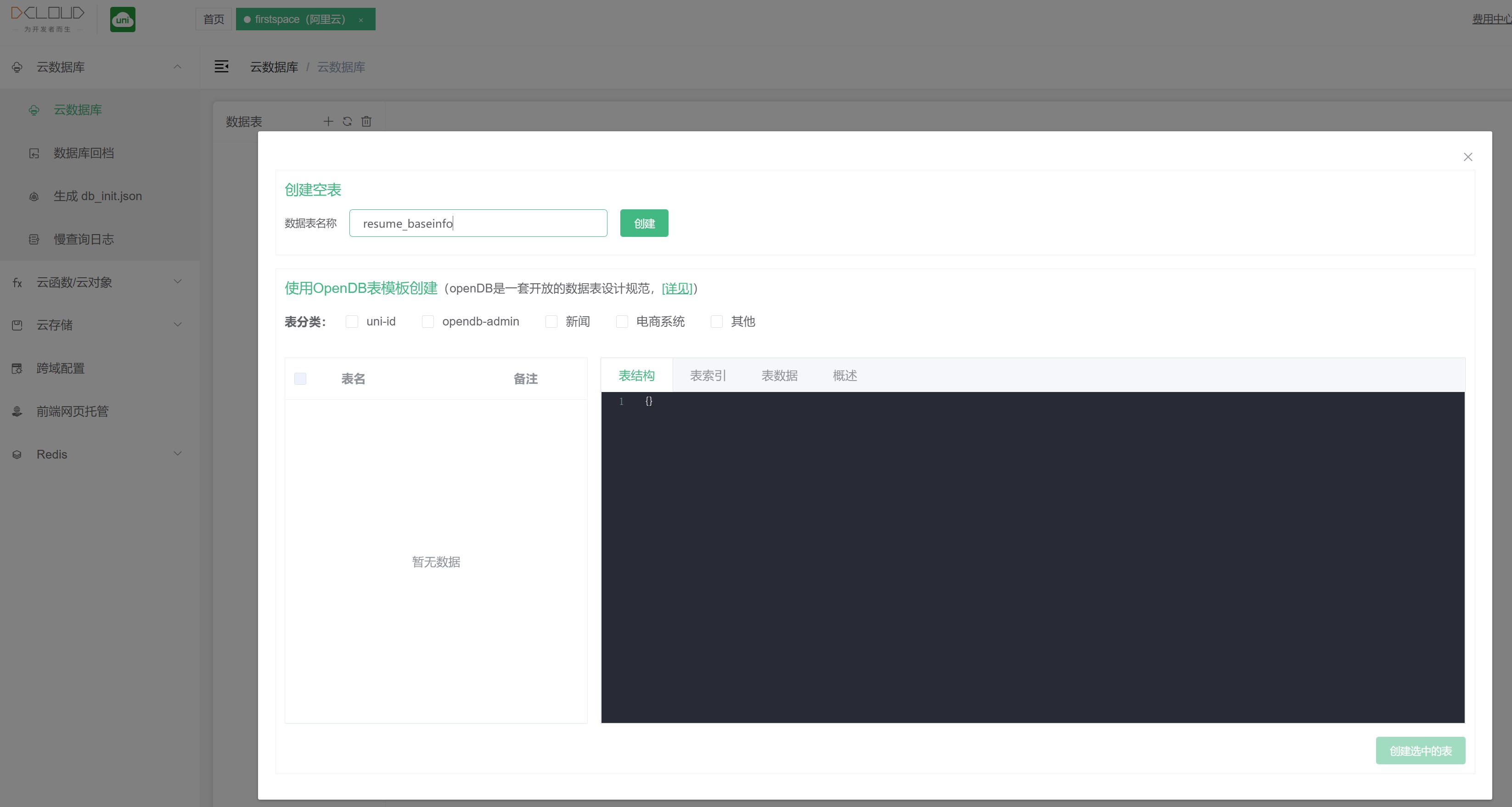
When creating a new table, you can select the ready-made opendb table template, select one or more template tables, and click the button at the bottom right to create.
There are 3 ways to create a table:
- Create in the web console
- In HBuilderX, right-click on the project root directory /uniCloud/database to create a new schema, which is created when uploading
- It is also possible to create tables in code, but it is not recommended, see below
# 3 components of the data table
Each data sheet contains 3 sections:
- data: data content
- index: index
- schema: data table format definition
Three parts of a data table can be seen in the uniCloud web console.
# Data content
data is the stored data record (record). Inside is a json document one by one.
Records can be added, deleted, modified, searched, sorted and counted. The API will be introduced later.
You can first create a record for the previous resume table in the web console.
enter a json
{
"name": "张三",
"birth_year": 2000,
"tel": "13900000000",
"email": "zhangsan@zhangsan.com",
"intro": "擅于学习,做事严谨"
}
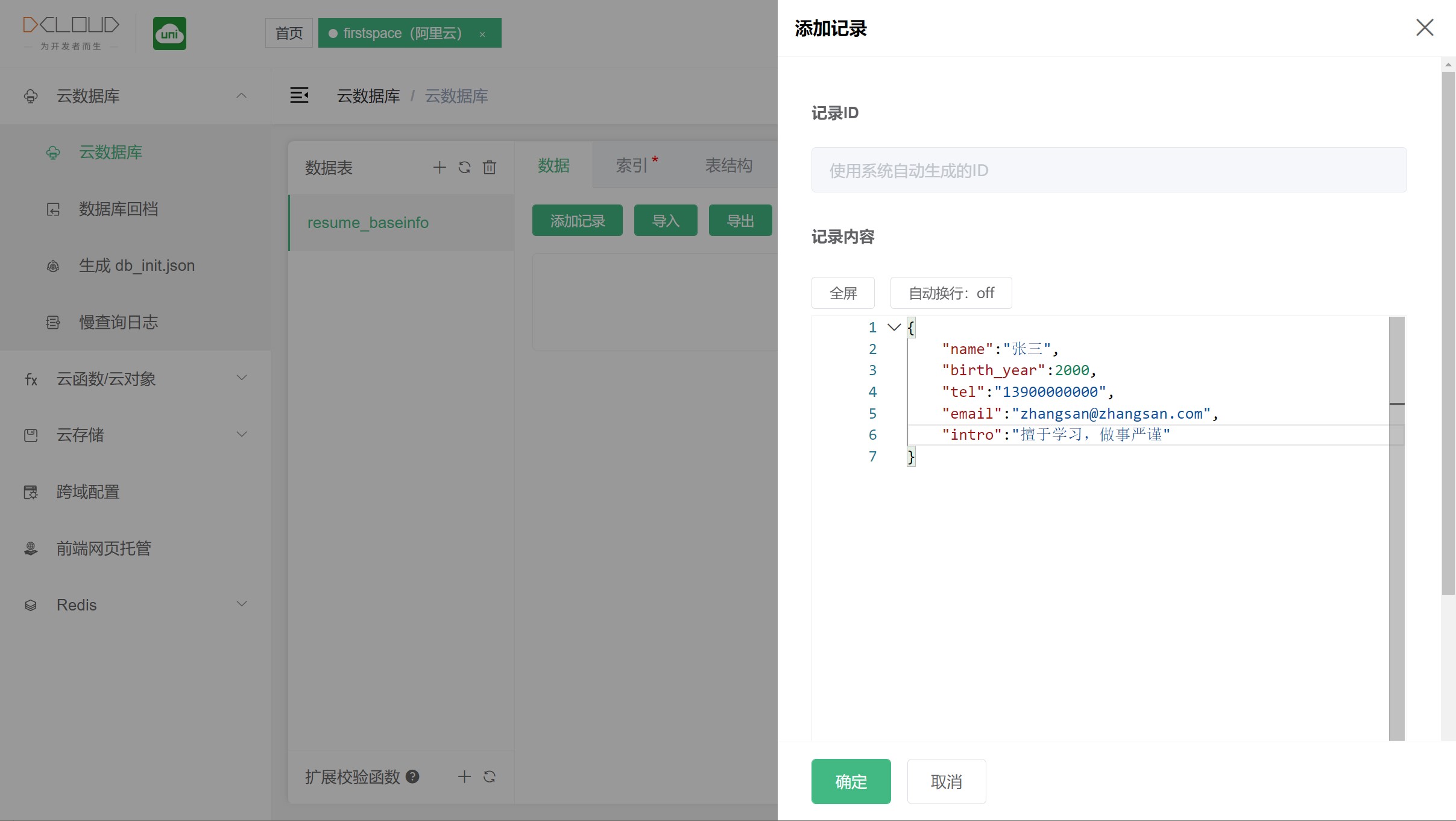
Create a new record, whether it is created in the web console or through the API, each record will have a _id field that is used as the unique identifier of the record.
The _id field is a default and non-deletable field in each data table. At the same time, it is also the index of the data table.
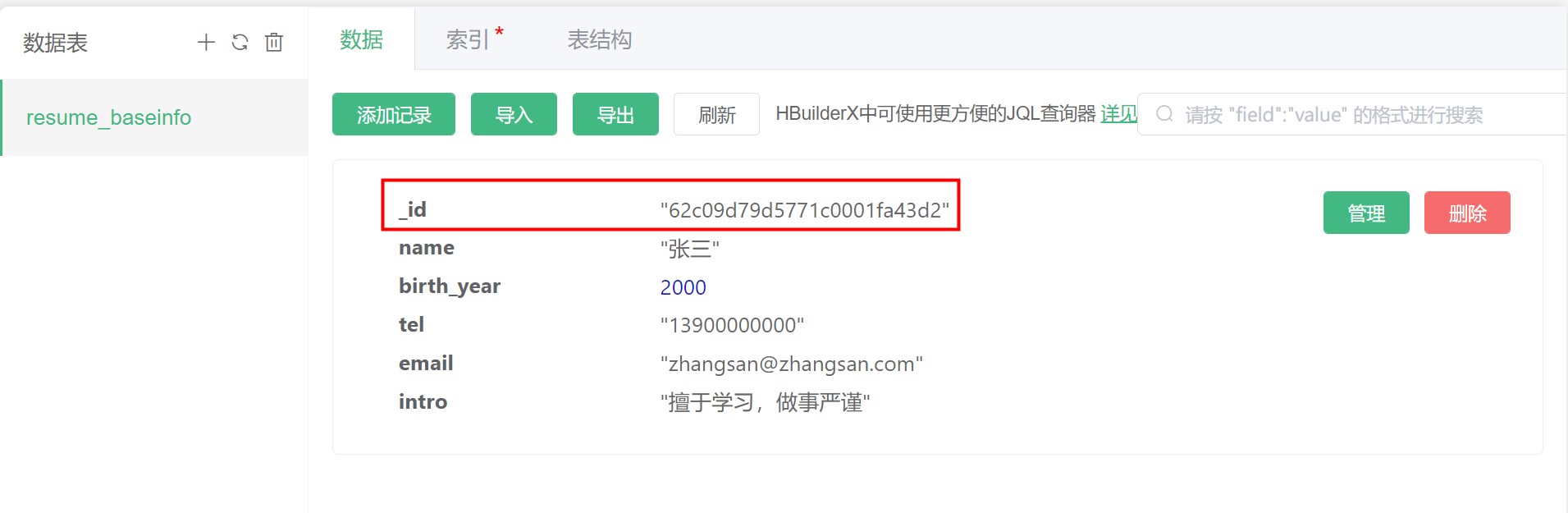
Alibaba Cloud uses standard mongoDB, _id is self-incrementing, and the _id of the record created later is always greater than the _id generated earlier. The natural number auto-increment fields of traditional databases are difficult to keep synchronized in large databases with multiple physical machines. Large databases use _id, which is a long, non-repetitive method that still maintains the auto-increment rule.
Tencent Cloud uses a self-developed database compatible with mongoDB, and _id is not self-incrementing
When inserting/importing data, you can also specify _id by yourself instead of using the automatically generated _id, so that data from other databases can be easily migrated to the uniCloud cloud database.
# Database index
The so-called index refers to selecting one or more fields among the many fields of the data table, and letting the database engine process these fields first.
A field set as an index can obtain faster query speed when querying (where) or sorting (orderBy) by this field.
However, it is not appropriate to set too many indexes, which will slow down data addition and deletion.
The newly created table has only one index _id by default.
A data table can have multiple fields set as indexes.
There are unique and non-unique indexes.
Unique index requires that the value of this field in multiple records of the entire data table cannot be repeated. For example _id is a unique index.
If there are two people named "Zhang San", then they are distinguished in the user data table by different _id.
If we want to query based on the name field, in order to improve the query speed, the name field can be set as a non-unique index at this time.
There are many index contents, and there are concepts such as "combined index", "sparse index", "geolocation index", and "TTL index". There is a separate document detailing indexes, see also: Database Index
Add the above index in the web console
Notice
- If there are multiple records with the same field in the record, setting the field as a unique index will fail.
- If a field has been set as a unique index, when adding and modifying records, if the value of the field already exists in other records, it will fail.
- If a field does not exist in the record, the value of the index field is null by default. If the index field is set as a unique index, it is not allowed to have two or more fields that are null or do not exist. record of. At this point, you need to set a sparse index to solve the problem of multiple null repetitions
# Data table format definition
DB Schema is a table structure description. Describe what fields the data table has, what the value field type is, whether it is required, data operation permissions, and many more.
Because of the flexibility of MongoDB, DB Schema is theoretically not necessary, and DB Schema is not required to operate the database using the traditional MongoDB API.
But if you use JQL, then DB Schema is a must.
DB Schema involves more content, see also the document: https://uniapp.dcloud.io/uniCloud/schema
# How the API operates the database
The cloud database of uniCloud has various operation modes.
- Supports cloud function operations and client operations.
- Supports operations using traditional MongoDB syntax, as well as JQL syntax operations.
uniCloud recommends using the JQL syntax to operate the database by default, which is a database operation syntax that is easier to use, more friendly to js developers, and more efficient in development. See details
JQL is supported both in cloud functions and in the uni-app client.
At the same time, uniCloud retains the use of traditional MongoDB's nodejs API to operate cloud databases in cloud functions.
| Runs on the cloud | Runs on the client | Supports DB Schema | |
|---|---|---|---|
| JQL Cloud Function | √ | √ | √ |
| Traditional MongoDB Client | √ | X | X |
There are several options for operating the database:
Use the client-side operation database first (called clientDB)
In traditional development, in fact, most server interface development is to verify the legitimacy of front-end data and identity, and then write SQL to operate the database and return JSON to the front-end. It's actually quite boring.
clientDB最大的好处就是不用写服务端代码,客户端直接操作数据库。因为uniCloud提供了DB Schema和uni-id,可以直接控制数据库的内容和权限校验。
clientDB also supports
action cloud functionas a supplement. When a client request to operate the cloud database is initiated, anaction cloud functioncan be triggered at the same time to pre- or post-process the database operation in the cloud.The following scenarios are not applicable to clientDB:
- Relevant database operation logic is not suitable to be exposed on the front end, such as lottery
- Operation of password type data (password type will not be passed to the front end) such as registration, password modification, etc. Under normal circumstances, developers do not involve related issues. Due to account management related to registration and password modification, the official has provided uni-id-pages, which contains uni-id-co cloud objects. Therefore, developers do not need to write the relevant logic themselves, just use this plug-in directly.
- 3rd party server callback. It is more common in places involving privacy such as login and payment. For example, the user's mobile phone number is obtained from the WeChat server, only the cloud is supported, and after the acquisition, it must be stored in the warehouse
Second, use the JQL extension library of cloud functions to operate the database
For scenarios where clientDB is not suitable, it is recommended to use JQL in cloud functions or cloud objects.
Scenarios where JQL is currently not applicable in cloud functions: use the set operator to dynamically modify field names (not field values). This scenario does not involve regular business, and JQL may improve and support this scenario in the future.
Unless the developer is very familiar with nodejs operating MongoDB, and needs to use the set operator to dynamically modify field names, etc., the traditional MongoDB writing method is not recommended.
The MongoDB API operates the database, cannot operate on the client, does not support DB Schema, does not support the jql query of HBuilderX, and cannot prompt the database table name and fields in the client code prompt.
Regardless of which method is used, there are many common concepts or functions. This document will describe these common content.
At the same time, there are special links for the three methods in the left navigation, describing their unique functions.
- Client operation database clientDB
- Use JQL syntax to operate database in cloud function
- Cloud functions use traditional MongoDB syntax to operate the database
# Get API
To operate the database through code, the first step is to obtain the database object in the service space.
const db = uniCloud.database(); //代码块为cdb
Type the code block cdb in js to quickly enter the above code.
Among them, when using the JQL extension library in the cloud function, there is still another job to be done, which is to specify the operation user identity. See details
// JQL usage example in cloud function
'use strict';
exports.main = async (event, context) => {
const dbJQL = uniCloud.databaseForJQL({ // 获取JQL database引用,此处需要传入云函数的event和context,必传
event,
context
})
return {
dbJQL.collection('book').get() // 直接执行数据库操作
}
};
# Get other service space database instance
If the current application only uses one service space, you can do the service space association in HBuilderX. There is no need to pass the configuration when obtaining the database instance of the current space. By default, calling the database method directly operates the database of the associated service space.
If the application needs to connect to other service space databases, it can pass the configuration of the corresponding service space when obtaining the database instance.
HBuilderX 3.2.11 and later versions support the client to initialize other service space database instances. Previously, it was only supported by the Tencent Cloud function environment. Alibaba Cloud function environment does not support this usage.
When calling uniCloud.database(), you can pass in the corresponding service space information (parameters are the same as uniCloud.init, refer to: uniCloud.init) to obtain the specified service space database instance.
Notice
- 云函数环境(仅支付宝小程序云与腾讯云支持)仅能通过init返回同账号下其他的腾讯云服务空间的数据库实例。
- 客户端环境(支付宝小程序云腾讯云阿里云均支持)可以通过init返回本账号下任意云厂商服务空间的数据库实例
Example
const db = uniCloud.database({
provider: 'tencent',
spaceId: 'xxx'
})
db.collection('uni-id-users').get()
Parameter Description
| 参数名 | 类型 | 必填 | 默认值 | 说明 |
|---|---|---|---|---|
| provider | String | 是 | - | aliyun、tencent |
| spaceId | String | 是 | - | 服务空间ID,注意是服务空间ID,不是服务空间名称 |
| clientSecret | String | 是 | - | 仅阿里云支持,可以在uniCloud控制台服务空间列表中查看 |
| endpoint | String | 否 | https://api.bspapp.com | 服务空间地址,仅阿里云支持。阿里云正式版需将此值设为https://api.next.bspapp.com |
| timeout | Number | 否 | 5000 | 仅支付宝小程序云支持,请求超时时间(单位:毫秒),默认为5秒。 |
# Create collection/table API
- Ali Cloud
When calling the add method to add a data record to a data table, if the data table does not exist, the data table will be created automatically. The following code adds a new piece of data to the table1 data table. If table1 does not exist, it will be created automatically.
const db = uniCloud.database();
db.collection("table1").add({name: 'Ben'})
- Tencent Cloud
Tencent Cloud provides a dedicated API for creating data tables. This API only supports running in cloud functions and does not support clientDB calls.
const db = uniCloud.database();
db.createCollection("table1")
- 支付宝小程序云
支付宝小程序云提供了专门的创建数据表的API,此API仅支持云函数内运行,不支持clientDB调用。
const db = uniCloud.database();
db.createCollection("table1")
Notice
- 如果数据表已存在,支付宝小程序云与腾讯云调用createCollection方法会报错
- 支付宝小程序云与腾讯云调用collection的add方法不会自动创建数据表,不存在的数据表会报错
- Alibaba Cloud does not have a createCollection method
- The table created by code has no index, schema, performance and function are affected, this method is not recommended
# Get collection/datatable object
After the data table is created, the data table object can be obtained through the API.
const db = uniCloud.database();
// Get a reference to the data table named `table1`
const resume = db.collection('resume');
Methods of Collection/DataTable Collection
Through db.collection(name), you can get a reference to the specified data table, and the following operations can be performed on the data table
| Type | Interface | Description |
|---|---|---|
| write | add | add record (trigger request) |
| Count | count | Get the number of records that meet the conditions |
| Read | get | Get the records in the data table, if the query condition is defined using the where statement, the matching result set will be returned (triggering the request) |
| citations | doc | Get a reference to the record with the specified id in this data table |
| Query conditions | where | Filter out matching records by specifying conditions, which can be used with query commands (eq, gt, in, ...) |
| skip | Skip the specified number of documents, often used for pagination, pass in offset. The clientDB component has encapsulated easier-to-use pagination, see also | |
| orderBy | Sort By | |
| limit | The limit of the returned result set (number of documents), with default and upper limit values | |
| field | Specify the field to be returned |
The methods of the collection object can add and check data, but deletion and modification cannot be directly operated. The collection object needs to obtain the specified record through doc or get, and then call the remove or update method to delete and modify it.
There are many APIs for data manipulation, please refer to the documentation separately:
Example
Here we use clientDB to implement a simple function of getting the records just entered into the resume table on the front end.
- Create a uni-app project, activate the uniCloud environment, and associate the service space where the resume table is located in the uniCloud initialization wizard; or use the old project to right-click the uniCloud directory to associate the service space.
- Right-click uniCloud/database under the project to download all DB Schemas.
- Open the newly downloaded resume.schema.json and change the "read" under the "permission" node from false to true. That is, set the table to allow any user to read (you can learn DB Schema in depth later)
- Write code on the client side pages/index/index.vue
<template>
<view class="content">
<button @click="testclientdb()">请求数据库</button>
</view>
</template>
<script>
export default {
data() {
return {}
},
methods: {
testclientdb() {
const db = uniCloud.database();
db.collection("resume").get().then((res) => {
// res is the database query result
console.log(res)
}).catch((e) => {
console.log(e)
});
}
}
}
</script>
- Run the project and click the button to print out the queried database content
res.result.datais the data in the data table resume.
# data type
The data types in the database are as follows:
*string: string + password: Special string extended in [DB Schema]. Used to save passwords. Such fields will not be passed to the front end through clientDB, and all users cannot read and write through clientDB, even admin administrators
- number: number
- Refine to int and double in [DB Schema]
- bool: boolean value
- date: time
- timestamp timestamp
- object: object
- file: A special object extended in [DB Schema], which is used for the information body of cloud storage files. It does not store the file directly, but a json object, including the name, path, file size and other information of the cloud storage file. (HBuilderX 3.1.0+)
- array: array
- null: Equivalent to a placeholder, indicating that a field exists but the value is empty.
- GeoPoint: geographic location point
- GeoLineStringLine: geographic path
- GeoPolygon: geographic polygon
- GeoMultiPoint: multiple geographic points
- GeoMultiLineString: multiple geographic paths
- GeoMultiPolygon: multiple geographic polygons
There are special documents for the data type of DB Schema, see details
# Date type
The Date type is used to represent time, accurate to milliseconds, and can be created with JavaScript's built-in Date object. It is important to note that when connecting to a local cloud function, the time created by this method is the current time of the client, not the current time of the server. Only the connection to the cloud function is the current time of the server.
In addition, we also provide a separate API to create the current time of the server, and use the serverDate object to create a mark of the current time of the server. This object only supports Tencent Cloud Space for the time being, when the request using the serverDate object arrives When the server processes, this field will be converted into the current time of the server. Even better, when constructing the serverDate object, we can also mark an offset from the current server time by passing in an object with an offset field. The time in milliseconds, so that we can achieve the following effect: specify a field as one hour after the server time.
// server current time
new db.serverDate()
// Using new Date() in the cloud function has the same effect as new db.serverDate()
//Add 1S to the current time of the server
new db.serverDate({
offset: 1000
})
// Using new Date(Date.now() + 1000) in the cloud function has the same effect as the above
# Geo type
支付宝小程序云暂不支持
# Point
Used to represent geographic points, uniquely mark a point with latitude and longitude, which is a special type of data storage.
Signature: Point(longitude: number, latitude: number)
Example:
new db.Geo.Point(longitude, latitude)
# LineString
Used to represent a geographic path, a line segment consisting of two or more Point s.
Signature: LineString(points: Point[])
Example:
new db.Geo.LineString([
new db.Geo.Point(lngA, latA),
new db.Geo.Point(lngB, latB),
// ...
])
# Polygon
Used to represent a geographic polygon (with or without holes), which is a geometric figure composed of one or more closed-loop LineString.
A Polygon composed of a ring is a polygon without holes, and a polygon composed of multiple rings is a polygon with holes. For a polygon (Polygon) consisting of multiple rings (LineString), the first ring is the outer ring and all other rings are the inner rings (holes).
Signature: Polygon(lines: LineString[])
Example:
new db.Geo.Polygon([
new db.Geo.LineString(...),
new db.Geo.LineString(...),
// ...
])
# MultiPoint
Used to represent a collection of multiple points Point.
Signature: MultiPoint(points: Point[])
Example:
new db.Geo.MultiPoint([
new db.Geo.Point(lngA, latA),
new db.Geo.Point(lngB, latB),
// ...
])
# MultiLineString
A collection of LineString used to represent multiple geographic paths.
Sign:MultiLineString(lines: LineString[])
Example:
new db.Geo.MultiLineString([
new db.Geo.LineString(...),
new db.Geo.LineString(...),
// ...
])
# MultiPolygon
A collection of Polygons used to represent multiple geographic polygons.
Signature: MultiPolygon(polygons: Polygon[])
Example:
new db.Geo.MultiPolygon([
new db.Geo.Polygon(...),
new db.Geo.Polygon(...),
// ...
])
# Difference from traditional development
Different from traditional development, there is a time limit for a single operation to connect to the database. Currently, the time limit for a single operation is as follows. If this time is exceeded, a timeout error will be reported. Under normal circumstances, you will not encounter a timeout error when a suitable index is set. How to optimize the query speed, please refer to: Database Performance Optimization
| 腾讯云 | 阿里云 | 支付宝小程序云 |
|---|---|---|
| 5秒 | 5秒 | 默认5秒;最大5分钟 |
If it is a batch of big data, you can refer to the recursive call of cloud functions to continuously execute multiple cloud functions to process a task Details
# Data import, export and backup
The uniCloud database provides a variety of data import, export and backup solutions.
- init_data.json、index.json等数据库初始化文件文件:
HBuilderX 3.97起支持常用于插件市场的插件做环境初始化。完整支持数据、索引、schema三部分。不适合处理大量数据,操作可能超时。可从uniCloud web控制台云数据库 => 生成初始化数据 导出。 - db_init.json:常用于插件市场的插件做环境初始化。完整支持数据、索引、schema三部分。不适合处理大量数据,操作可能超时。HBuilderX 3.97及之后版本需要拆分为上面一种方式对应的文件,可以在项目管理器选中db_init.json右键初始化数据库时自动拆分。
- 数据库回档备份和恢复,不支持schema
- 数据库导入导出,jsonl格式数据,仅数据,无索引及schema
In addition to the above three methods, developers can also programmatically handle the import and export of data. If a large amount of data operations are performed, it is recommended to operate in the local cloud function environment of HBuilderX, which can avoid triggering the cloud function timeout limit in the cloud.
The following describes the use of the three methods in detail:
# 数据库初始化
HBuilderX 3.97起支持
旧规范中的db_init.json废弃,但是仍保留db_init.json上的初始化菜单,对db_init.json文件执行初始化操作时,其中的初始化数据、索引、schema会被拆分成多个文件。
注意
此方式导入导出会消耗数据库读写次数,不适用于大数据量导入导出,仅适用于项目初始化。
HBuilderX 3.97及以上版本,uniCloud内database目录支持直接右键进行数据库初始化。database目录下支持以下几种文件类型
- 表名.init_data.json:数据表初始化数据
- 表名.index.json:表的索引配置,内容示例见下方初始化索引配置示例
- 表名.schema.json:表结构,参考:DB Schema表结构
- 表名.schema.ext.json:DB Schema扩展js,参考:DB Schema扩展js
- validateFunction/xxx.js:扩展校验函数,参考:validateFunction扩展校验函数
- package.json:主要用于配置schema扩展可以使用的公共模块,在database目录右键可以配置这些依赖
在执行数据库初始化操作时,上述文件都会被上传到云端。
# 初始化数据注意事项
web控制台导出时默认不包括_id字段,在导入时,数据库插入新记录时会自动补_id字段。如果需要指定_id,需要手工补足数据。
在db_init.json内可以使用以下形式定义Date类型的数据:
{
"dateObj": { // dateObj字段就是日期类型的数据
"$date": "2020-12-12T00:00:00.000Z" // ISO标准日期字符串
}
}
# 初始化索引配置示例
注意下面的示例仅为演示,实际配置时不要带注释
// 表名.index.json
[{ // 索引列表
"IndexName": "index_a", // 索引名称
"MgoKeySchema": { // 索引规则
"MgoIndexKeys": [{
"Name": "index", // 索引字段
"Direction": "1" // 索引方向,1:ASC-升序,-1:DESC-降序,2dsphere:地理位置
}],
"MgoIsUnique": false, // 索引是否唯一
"MgoIsSparse": false // 是否为稀疏索引,请参考 https://uniapp.dcloud.net.cn/uniCloud/db-index.md?id=sparse
}
}]
# db_init.json initializes the database
HBuilderX 3.97及之后版本需要拆分为上面一种方式对应的文件,可以在项目管理器选中db_init.json右键初始化数据库时自动拆分。
注意
此方式导入导出会消耗数据库读写次数,不适用于大数据量导入导出,仅适用于项目初始化。
db_init.json defines a json format, which contains table name, table data, table index and other table related data.
In HBuilderX, you can place the db_init.json file in the cloudfunctions directory of the project (HBuilderX 2.5.11 - 2.9.11 versions) or uniCloud/database directory (HBuilderX 3.0+ versions), right-click on the file, and press db_init .json description, create the corresponding table in the cloud service space, initialize the data, index and schema in the table.
This feature is especially suitable for plugin authors to quickly initialize the database environment required by the plugin.
Data format of db_init.json
db_init.json contains three parts: data content (data), data table index (index), data table structure (schema), the form is as follows
**Note: The schema of HBuilderX 3.0.0 and above is no longer placed in db_init.json, but is placed in the uniCloud/database/ directory independently. **
The detailed adjustments are as follows:
- db_init.json location moved from
cloudfunctions/db_init.jsontouniCloud/database/db_init.json - The schema is no longer placed in db_init.json, and each table has a separate schema file. For example, the schema corresponding to the news table is
uniCloud/database/news.schema.json - Schema can be created by right-clicking on the
uniCloud/databasedirectory - When you right-click on the
db_init.jsonfile to initialize the cloud database, it will still bring the schema to initialize the database. In addition to the schema, HBuilderX3.0.0 or later uses db_init.json to initialize the database and will also bring the extended verification function. The extended verification function is located in Under theuniCloud/database/validateFunctiondirectory, see the extended validation function documentation: validateFunction
** db_init.json example prior to HBuilderX version 3.0.0**
{
"collection_test": { // 集合(表名)
"data": [ // 数据
{
"_id": "da51bd8c5e37ac14099ea43a2505a1a5", // 一般不带_id字段,防止导入时数据冲突。
"name": "tom"
}
],
"index": [{ // 索引
"IndexName": "index_a", // 索引名称
"MgoKeySchema": { // 索引规则
"MgoIndexKeys": [{
"Name": "index", // 索引字段
"Direction": "1" // 索引方向,1:ASC-升序,-1:DESC-降序,2dsphere:地理位置
}],
"MgoIsUnique": false, // 索引是否唯一
"MgoIsSparse": false // 是否为稀疏索引,请参考 https://uniapp.dcloud.net.cn/uniCloud/db-index.md?id=sparse
}
}],
"schema": { // HBuilderX 3.0.0以上版本schema不在此处,而是放在database目录下单独的`表名.schema.json`文件内
"bsonType": "object",
"permission": {
".read": true,
".create": false,
".update": false,
".delete": false
},
"required": [
"image_url"
],
"properties": {
"_id": {
"description": "ID,系统自动生成"
},
"image_url": {
"bsonType": "string",
"description": "可以是在线地址,也支持本地地址",
"label": "图片url"
}
}
}
}
}
Right-click on the above db_init.json in HBuilderX, you can initialize the database to the cloud service space, create a collection_test table, and set the index index and schema of the table according to the above json configuration, and insert the data under data.
opendb table, when initialized in db_init.json, it is not recommended to customize index and schema. The system will automatically read the latest index and schema from the opendb specification.
Use db_init.json to import the database
In HBuilderX, right-click db_init.json in the cloudfunctions directory under the project, and then select Initialize cloud database. Import the contents of db_init.json into the cloud.
Precautions:
- Currently
db_init.jsonis in the form of synchronous import and cannot import a large amount of data. To import large amounts of data, please use the database import function of the web console. - If the table name in
db_init.jsonis the same as any table name in opendb, and there is no schema and index written in the table name indb_init.json, the corresponding table in the latest opendb specification will be automatically pulled during initialization The schema and index of the table. - If the data table in
db_init.jsonalready exists in the service space, and the table indb_init.jsoncontains schema and index, the schema will be replaced during initialization, the new index will be added, and the existing index will be added Not affected.
The way db_init.json is generated
On the database interface of the uniCloud web console, click Generate db_init.json in the left navigation, and the content, index, and table structure of the selected table will be exported to the db_init.json file.
Precautions:
- If the table name is the same as any table name in opendb, the schema and index will not be included when exporting from the web console.
- The
_idfield is not included by default when exporting from the web console. When importing, the database will automatically fill in the_idfield when inserting new records. If you need to specify_id, you need to manually supplement the data.
Data of type Date can be defined in db_init.json in the following form:
{
"dateObj": { // dateObj字段就是日期类型的数据
"$date": "2020-12-12T00:00:00.000Z" // ISO标准日期字符串
}
}
# Database backup and restore
uniCloud will automatically back up the database once every morning and keep it for up to 7 days. This frees developers from worrying about data loss.
Instructions
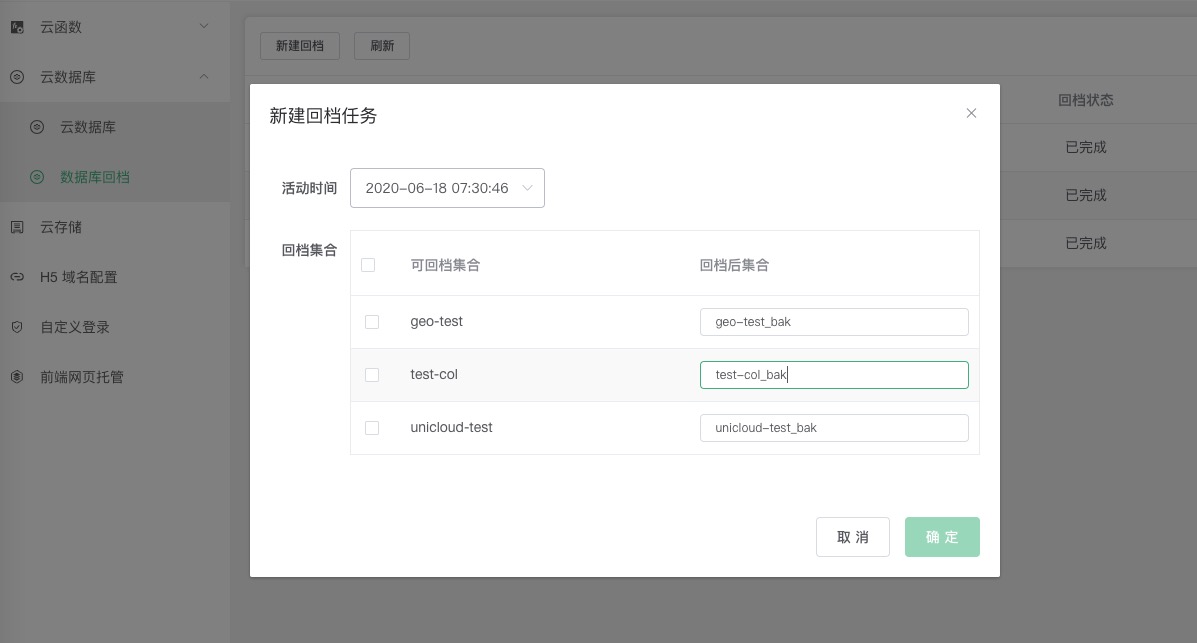
- Log in to uniCloud background
- Click
Cloud Database --> Database Rollbackon the left menu, and clickNew Rollback - Select the rollback time
- Select the table that needs to be backed up (note: the table cannot have the same name as the existing table after being backed up, if you need to rename the table, you can do it in the table list)
# Data export to file
此功能主要用于导出整个表的数据,导出文件为jsonl格式
jsonl格式示例,形如下面这样每行一个json格式的数据库记录的文件
{"a":1}
{"a":2}
usage
- Enter the uniCloud web console, select the service space, or directly right-click on the HBuilderX cloud function directory
cloudfunctionsto open the uniCloud web console - Enter the cloud database and select the table to which you want to import data
- Click the Export button
- Select the export format, if you select the csv format, you also need to select the export field
- Click the OK button and wait for the download to start
Notice
- The exported json file is not json in general, but a text file with one json data per line
- Field options must be filled when exporting to csv format. Separate fields with commas. For example:
_id, name, age, gender - Exporting to csv format will lose data types, if you need to migrate the database, please export to json format
- When the amount of data is large, it may take a while for the download to start
# Import data from file
The db_init.json provided by uniCloud is mainly for initializing the database and is not suitable for importing large amounts of data. Different from db_init.json, the data import function can import a large amount of data. Currently, it supports importing file data in CSV and JSON format (see the notes below for json format).
usage
- Enter the uniCloud web console, select the service space, or directly right-click on the HBuilderX cloud functions directory
cloudfunctionsto open the uniCloud web console - 进入云数据库选择希望导入数据的表
- 点击导入,选择jsonl文件或csv文件
- Select the conflict handling mode (please see the notes below for handling conflict mode)
- Click the OK button and wait for the import to complete.
Notice
- Currently the maximum import file limit is 50MB
- Import and export files cannot preserve indexes and schemas
- 导入导出csv时数据类型会丢失,即所有字段均会作为字符串导入
- 冲突处理模式为设定记录_id冲突时的处理方式,
insert表示冲突时依旧导入记录,此时会由于_id冲突报错。upsert表示冲突时更新已存在的记录。
If it is json format data that is spliced by yourself, please note: if there is a scenario where table A is associated with fields in table B, you need to ensure that the associated fields are consistent in A and B (special attention should be paid to various fields associated with _id)
example:
correct example
// The data is formatted here for the convenience of viewing the data. The json file required for the actual import is one record per line
// article table
{
"user_id": {
$oid: "601cf1dbf194b200018ed8ec"
}
}
// user table
{
"_id": {
$oid: "601cf1dbf194b200018ed8ec"
}
}
Error example
// The data is formatted here for the convenience of viewing the data. The json file required for the actual import is one record per line
// article table
{
"user_id": "601cf1dbf194b200018ed8ec"
}
// user table
{
"_id": {
$oid: "601cf1dbf194b200018ed8ec"
}
}
# Migration between cloud providers
Documentation moved to: Migrating databases between cloud providers